Total amount:
plus VAT.
Artificial intelligence doesn't need supercomputers and companies are already collecting data from which valuable insights can be gained with the help of an AI model. Our AI competence center offers you many advantages for implementing AI in your embedded system:
- In-house data scientist as a direct contact
- AI kits for data mining
- AI training + online seminars
- Agile team for software + hardware development
- Analysis + solution advice
AI competence center _ Our specialized know-how for your development
From the model
to the embedded
AI application
In order to bring the possibilities of AI solutions closer to our customers and to offer the best possible support from a single source, we have founded a competence center for AI. The team around our in-house data scientist Dr. Jan Werth with many years of experience in the use of artificial intelligence shows you the possibilities of machine learning and finds the right solution for your project. According to your own wishes and competencies, we complement the team agilely with cloud and security experts as well as software and hardware developers.
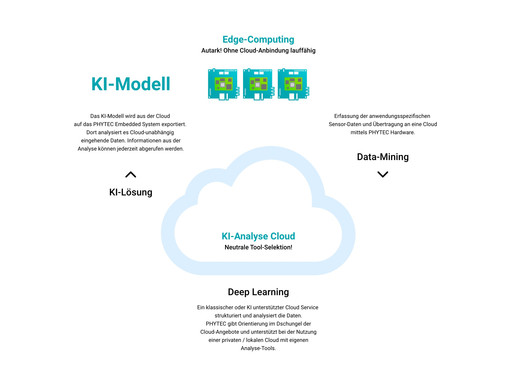
CLOUD computing
Cloud computing describes the relocation of computing power to the cloud. The results can be distributed directly online.
EDGE computing
With edge computing, the data is processed at the point of origin. The models for processing can be created via cloud computing, but run locally. A cloud connection is possible, but not absolutely necessary. Edge computing is therefore also suitable for security-critical applications.
You have questions about the use of AI
or do you need support for your project?
The PHYTEC AI Competence Center will be happy to help you.
AI, Machine & Deep Learning _ Has been around for a long time. Why now? What has changed?
The basic ideas and algorithms of machine learning have long been known. In the last 50 years, however, decisive framework conditions have changed that are now leading to the rapid success of AI:
- Increased computing power
- Liberalization of computing power through cloud computing
- Adaptation of computing power
- Exponential data increase
- Inexpensive storage space
- Easy to use open source analysis tools
The increased computing power makes it possible to cope with the resource-demanding computing processes in manageable times. Equally important is the liberalization of computing power, which enables every user to master complicated models without having to set up and maintain a high-performance infrastructure beforehand. Today we borrow computing power - exactly as much as we need and only for the necessary period of time. At the same time, the amount of data that we have available to train modern algorithms is increasing exponentially. It is estimated that 90% of all data has been generated in the last two years. From 2018 the two zettabyte mark of data was exceeded. This means that after 2018, over two zettabytes of data will be generated annually. This data explosion feeds the success of data-hungry algorithms like deep learning. It is also important that open source platforms such as Phyton have been optimized for the use of machine learning. Since 2015, with the introduction of Keras and TensorFlow, deep learning has also been integrated into Phython in a user-friendly and license-free manner.

These three terms denote sub-categories of artificial intelligence.
Machine Learning
refers to learning from examples. The algorithm does not learn all the examples by heart, but learns the basic characteristics of the examples and can then apply them to unseen data.
Deep Learning
is a sub-category of machine learning and works on similar principles. The crucial difference is the independent adaptation of the parameters in order to obtain optimized results. With deep learning, complex questions with multiple, non-linear dependencies can be solved.
Big Data
refers to the use of large amounts of data which, due to their size, cannot be processed by conventional means. Big data can be analyzed with machine learning or deep learning.
Nothing works without hardware _ Smart ones Embedded systems with integrated machine learning
Collecting, storing, structuring and analyzing data are the challenges for the use of artificial intelligence. The computationally intensive part of AI is creating a model. At the same time, hardware is required that records this data, preprocesses it, sends it to the computer / server or processes it itself.
In order to ensure optimal functionality as an edge device, the hardware must be powerful and energy-efficient. PHYTEC combines the building blocks from many years of experience in the field of hardware development and kernel/software development with expertise in the field of data analytics. Get straight into AI development with our AI Kits.

AI expert Dr. Jan Werth _ at the Embedded World 2020
Online seminars _ Helpful embedded knowledge explained in a nutshell in short video sessions

In informative online seminars with our experts and partners, we will inform you about exciting topics from the embedded industry.
You will get a free insight into new hardware and software solutions and learn more about special offers.
Our embedded experts are there for you!
Secure your personal consultation appointment quickly, easily and free of charge.
30 minutes exclusively for you and your project!
Other interesting topics: